Gestión de infraestructuras virtuales
Objetivos de la asignatura
-
Diseñar, construir y analizar las prestaciones de un centro de proceso de datos virtual.
-
Documentar y mantener una plataforma virtual.
-
Realizar tareas de administración en infraestructura virtual.
Objetivos específicos
- Aprender lenguajes de configuración usados en infraestructuras virtuales.
- Saber cómo aplicarlos en un caso determinado.
- Conocer los sistemas de gestión de la configuración, provisionamiento y monitorización más usados hoy en día.
Introducción
Los contenedores son un ejemplo de virtualización que ya tienen ciertas características de las máquinas virtuales, como el aislamiento y la gestión independiente. Pero en general, un contenedor aisla un solo servicio y en arquitecturas de aplicaciones modernas es muchas veces necesario crear máquinas virtuales con características determinadas tales como diferentes sistemas operativos o diferentes características del sistema de ficheros o kernel, por lo que se hace necesario usar herramientas para crear y configurar estos entornos.
Estas herramientas se denominan, en general, gestores de configuración o sistemas de orquestación. Vagrant es uno de ellos y se sitúa al nivel más alto, pero también hay otros: Chef, Salt y Puppet, por ejemplo, que se pueden usar desde Vagrant pero que también se usan para gestionar configuraciones complejas de sistemas en la nube. Todos son libres, pero tienen características específicas que hay que tener en cuenta a la hora de elegir uno u otro. En el caso específico de gestión de configuraciones de sistemas operativos se trata de gestionar automáticamente todas las tareas de configuración de un sistema, automatizando la edición de ficheros de configuración, instalación de software y configuración del mismo, creación de usuarios y autenticación, de forma que se pueda hacer de forma automática y masiva.
Veremos primero un ejemplo de trabajo en un gestor de nube comercial usando el CLI libre, y a continuación veremos diferentes ejemplos de sistemas de configuración, empezando por Chef.
Trabajando con máquinas virtuales en la nube
Azure permite, tras la creación de almacenamiento virtual, la creación de máquinas virtuales, como es natural. Se puede crear una máquina virtual desde el panel de control, pero también desde la línea de órdenes. Primero hay que saber qué imágenes hay disponibles:
azure vm image list
Por ejemplo, se puede escoger la imagen
b39f27a8b8c64d52b05eac6a62ebad85__Ubuntu_DAILY_BUILD-trusty-14_04-LTS-amd64-server-20131221-en-us-30GB
de la última versión de Ubuntu (para salir dentro de cuatro meses) o alguna más
probada como la
b39f27a8b8c64d52b05eac6a62ebad85__Ubuntu-13_10-amd64-server-20131215-en-us-30GB
Con
azure vm image show b39f27a8b8c64d52b05eac6a62ebad85__Ubuntu-13_10-amd64-server-20131215-en-us-30GB
nos muestra detalles sobre la imagen; entre otras cosas dónde está disponible y sobre si es Premium o no (en este caso no lo es). Con esta (o con otra) podemos crear una máquina virtual
azure vm create peasomaquina b39f27a8b8c64d52b05eac6a62ebad85__Ubuntu-13_10-amd64-server-20131215-en-us-30GB peasousuario PeasoD2clav= --location "West Europe" --ssh
En esta clave tenemos que asignar un nombre de máquina (que se
convertirá en un nombre de dominio peasomaquina.cloudapp.net, un
nombre de usuario (como peasousuario) que será el superusuario de la
máquina, una clave como PeasoD2clav= que debe incluir mayúsculas,
minúsculas, números y caracteres especiales (no uséis esta, hombre),
una localización que en nuestro caso, para producción, será
conveniente que sea West Europa pero que para probar podéis
llevárosla a la localización exótica que queráis y, finalmente, para
poder acceder a ella mediante ssh, la última opción, si no no tengo
muy claro cómo se podrá acceder. Una vez hecho esto, conviene que se
cree un par clave pública/privada y se copie al mismo para poder
acceder fácilmente.
La máquina todavía no está funcionando. Con azure vm list nos
muestra las máquinas virtuales que tenemos y el nombre que se le ha
asignado y finalmente con azure vm start se arranca la máquina y
podemos conectarnos con ella usando ssh Una de las primeras cosas
que hay que hacer cuando se arranque es actualizar el sistema para
evitar problemas de seguridad. A partir de ahí, podemos instalar lo
que queramos. El arranque tarda cierto tiempo y dependerá de la
disponibilidad de recursos; evidentemente, mientras no esté arrancada
no se puede usar, pero conviene de todas formas apagarla con
azure vm shutdown maquina
cuando terminemos la sesión y no sea necesaria, sobre todo porque, dado que se pagan por tiempo de uso, se puede incurrir en costes innecesarios.
Crear una máquina virtual Ubuntu e instalar en ella alguno de los servicios que estamos usando en el proyecto de la asignatura.
Trabajar con estas máquinas virtuales como se tratara de máquinas reales no tiene mucho sentido. El uso de infraestructuras virtuales, precisamente, lo que permite es automatizar la creación y provisionamiento de las mismas de forma que se puedan crear y configurar máquinas en instantes y personalizarlas de forma masiva. Veremos como hacerlo en el siguiente tema.
Usando Chef para provisionamiento
En el año 2018, Chef ha introducido una nueva versión denominada Chef Workstation que hace más simple trabajar de forma local o remota. Consultad los recursos de la misma para saber más
Este vídeo es una introducción a Chef Workstation, a la vez que explica los conceptos básicos para trabajar con los cookbooks de Chef. El repositorio de la presentación incluye varios cookbooks de ejemplo.
Ansible para provisionamiento
Las principales alternativas a Chef son Ansible, Salt y Puppet. Todos ellos se comparan en este artículo, aunque los principales contendientes son Puppet y Chef, sin que ninguno de los dos sea perfecto.
De todas ellas, vamos a ver Ansible que parece ser uno de los que se está desarrollando con más intensidad últimamente. Ansible es sistema de gestión remota de configuración que permite gestionar simultáneamente miles de sistemas diferentes. Está basado en YAML para la descripción de los sistemas y escrito en Python.
Se puede instalar como un módulo de Python, usando por ejemplo la utilidad de
instalación de módulos pip (que habrá que instalar si no se tiene);
también se puede instalar directamente desde su repositorio PPA en Ubuntu
sudo apt-add-repository ppa:ansible/ansible
sudo apt-get install ansible
Ansible va a necesitar tres ficheros para provisionar una máquina virtual.
- Un fichero de configuración general, que se suele llamar
ansible.cfg - Un fichero de configuración específica de los hosts con los que se va a
trabajar o inventario , que habitualmente se llama
ansible_hosts. - Una o varias recetas o playbooks que indican qué se va a instalar, y declara el estado en el que se debe encontrar el sistema al final.
Comencemos por el fichero de configuración, tal como este:
[defaults]
host_key_checking = False
inventory = ./ansible_hosts
Lo principal es la primera opción, que permite que la conexión con nuevas
máquinas virtuales por ssh no pregunte si se acepta la clave nueva de una
nueva MAC detectada. La segunda instrucción indica dónde se va a encontrar, por
omisión, el fichero de inventario, en este caso en el mismo directorio.
Cada máquina que se añada al control de Ansible se tiene que añadir a un fichero, llamado inventario, que contiene las diferentes máquinas controladas por el mismo. Por ejemplo
echo "ansible-iv.cloudapp.net" > ~/ansible_hosts
se puede ejecutar desde el shell para meter (echo) una cadena con
una dirección (en este caso, una máquina virtual de Azure) en el
fichero ansible_hosts situado en mi directorio raíz. El lugar de ese
fichero es arbitrario, por lo que habrá que avisar a Ansible donde
está usando una variable de entorno:
export ANSIBLE_HOSTS=~/ansible_hosts
Y, con un nodo, ya se puede comprobar si Ansible funciona con
ansible all -u jjmerelo -m ping
Esta orden hace un ping, es decir, simplemente comprueba si la
máquina es accesible desde la máquina local. -u incluye el nombre
del usuario (si es diferente del de la máquina local); habrá que
añadir --ask-pass si no se ha configurado la máquina remota para
poder acceder a ella sin clave.
De forma básica, lo que hace Ansible es simplemente ejecutar comandos de forma remota y simultáneamente. Para hacerlo, podemos usar el inventario para agrupar los servidores, por ejemplo
[azure]
iv-ansible.cloudapp.net
crearía un grupo azure (con un solo ordenador), en el cual podemos
ejecutar comandos de forma remota
ansible azure -u jjmerelo -a df
nos mostraría en todas las máquinas de Azure la organización del
sistema de ficheros (que es lo que hace el comando df). Una vez más,
-u es opcional.
Esta orden usa un módulo de ansible y se puede ejecutar también de esta forma:
ansible azure -m shell ls
haciendo uso del módulo shell. Hay muchos
más módulos
a los que se le pueden enviar comandos del tipo “variable = valor”. Por
ejemplo, se puede trabajar con servidores web o
copiar ficheros
o
incluso desplegar aplicaciones directamente usando el módulo git.
Nosotros nos vamos a conectar a una máquina virtual local creada con Vagrant, usando este inventario:
[vagrantboxes]
debianita ansible_ssh_port=2222 ansible_ssh_private_key_file=.vagrant/machines/default/virtualbox/private_key
[vagrantboxes:vars]
ansible_ssh_host=127.0.0.1
ansible_ssh_user=vagrant
Como se ha creado con vagrant, la máquina local va a usar por
omisión el puerto 2222 y además la clave privada que se usa (y que
generalmente no tenemos que encontrar si accedemos con vagrant ssh)
está en el camino indicado. Las variables por omisión que vamos a usar
en la conexión también están en ese fichero: el nombre de usuario y la
dirección IP. Además, usamos el nombre debianita que es el que le
vamos a asignar a estas máquinas virtuales. El término vagrantboxes
permite que nos refiramos de forma genérica a una serie de máquinas,
aunque en este caso tengamos solo una.
Como se ve, este fichero de hosts permite definir parámetros para una o varias máquinas. En el caso de usar un host en la nube se haría de forma similar.
Finalmente, el concepto similar a las recetas de Chef en Ansible son los
playbooks,
ficheros en YAML que le dicen a la máquina virtual qué es lo que hay que
instalar en tareas o tasks, de la forma que se ve en
este fichero.
---
- hosts: all
become: yes
tasks:
- name: Instala git
apt: pkg=git state=present
En este caso all va a ser una denominación genérica de todos los
hosts, pero a continuación le indicamos con become que es necesario
adquirir privilegios para ejecutar el resto del fichero. Las tareas se
llevarán a cabo secuencialmente, pero solo tenemos una, que invoca el
comando apt, indicándole que el paquete git tiene que estar presente.
ansible-playbook basico.yaml
Esto dará, si todo ha ido bien, un resultado como el siguiente (para uno que instalara emacs en una versión anterior)
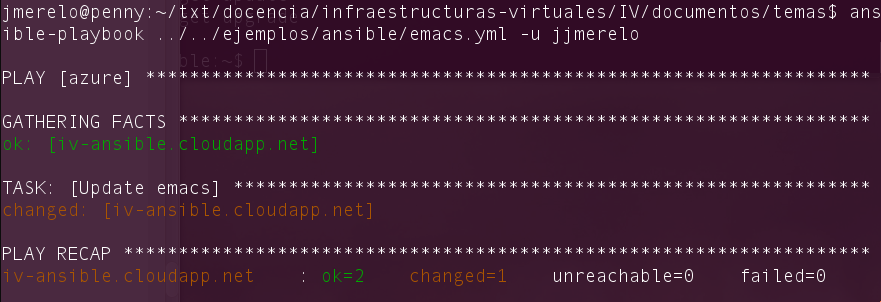
Ejecuciones sucesivas arrojarán el mismo resultado, pero en la salida
ansible indicará que ya está instalado, por lo que no hace
falta. Comprobará que está presente, y no hará nada más.
Desplegar la aplicación de DAI o de cualquier otra asignatura donde se tenga ya el código fuente con todos los módulos necesarios usando un playbook de Ansible.
También se pueden instalar varios paquetes a la vez, como en este playbook que instala node:
---
- hosts: vagrantboxes
become: yes
tasks:
- name: Instala paquetes
apt:
pkg: ['curl', 'build-essential', 'libssl-dev', 'nodejs', 'npm']
En vez de usar un genérico all en este caso estamos especificando un
conjunto de nodos, que en realidad es el mismo, porque no tenemos
más. El formato de instalación de paquetes es ligeramente diferente,
pero nos permite instalar diferentes paquetes a la vez.
Ansible usa el concepto de rol para agrupar en un directorio una serie de tareas que puedan estar relacionadas; por ejemplo, un framework específico junto con lo que ese framework necesite, como un conjunto de herramientas. A un nivel muy básico, un rol es el equivalente a un paquete, módulo o clase, simplemente una agrupación de funciones dentro de un directorio que permite estructurar el provisionamiento de un módulo o conjunto de módulos.
Los roles fueron introducidos en la versión 1.2 de ansible, en el año 2013. Es poco probable que tengas una versión anterior, pero podría suceder.
Un rol abarca variables, tareas y otro tipo de metadatos, y se
agruparán en un directorio con un nombre determinado, por ejemplo, el
rol ol estará en el directorio (a partir del playbook que lo use)
roles/ol. Dentro de ese directorio habrá diferentes subdirectorios,
tales como tasks para tareas o vars para variables. Por ejemplo,
vamos a declarar un rol common que suele usarse para agrupar tareas
que van a ser comunes a varios playbooks en un proyecto. Este será el
playbook:
---
- hosts: all
become: yes
roles:
- common
Normalmente, habría otras tareas (no comunes) en este playbook.
En el directorio roles/common/tasks estará este
fichero
---
- name: Instala básicos
apt:
pkg: ['git','make','perl']
Como ya está calificado como tareas, en este fichero se pondría
directamente lo que estaría dentro de la lista de tasks en un
playbook.
Este sistema de roles, además, permite extender ansible con un sistema llamado
Galaxy, una colección de roles libres
aportados por la comunidad. Estos roles se pueden descargar e instalar
en el propio repositorio, pero también se pueden instalar en un lugar
común para todos. Por ejemplo, podemos instalar uno para trabajar con
diferentes versiones de node
llamado
geerlingguy.nodejs de
esta forma:
ansible-galaxy install geerlingguy.nodejs
Se usa en un playbook usando el nombre completo, tras instalarlo:
---
- hosts: debianita
become: yes
vars_files:
- vars/main.yml
roles:
- geerlingguy.nodejs
En este caso el rol lo que incluye son variables, en vez de tareas,
con concreto la indicada en la clave vars_files. Ese fichero
contiene solamente:
nodejs_version: "12.x"
indicando la versión del fichero que se va a instalar. Esa variable la usará el rol para instalar la versión de node correspondiente.
Un tutorial bastante extenso de diferentes capacidades de ansible en Guru99. Digital Ocean también nos enseña aquí diferentes características de los playbooks que se pueden usar.
Crear un rol common que haga ciertas tareas comunes que vayamos a
usar en todas las máquinas virtuales de los microservicios de la
asignatura (o, para el caso, cualquier otra asignatura).
En esta sección hemos creado a mano la máquina virtual sobre la que vamos a trabajar. A continuación veremos como automatizar también este proceso, en el espíritu de infraestructura como código.
Orquestación de máquinas virtuales
Vagrant in 5 minutes hace exactamente es, explicar Vagrant en cinco minutos.
A un nivel superior al provisionamiento de máquinas virtuales está la configuración, orquestación y gestión de las mismas, herramientas como Vagrant ayudan a hacerlo, aunque también Puppet e incluso Juju pueden hacer muchas de las funciones de Vagrant (no todas, y por eso hoy en día es la herramienta estándar para configuración de máquinas virtuales). La ventaja de Vagrant es que permite gestionar el ciclo de vida completo de un conjunto de máquinas virtuales, desde la creación hasta su destrucción pasando por el provisionamiento, la interconexión entre ellas, y la monitorización o conexión con la misma. Además, permite trabajar con todo tipo de hipervisores y provisionadores tales como los que hemos visto anteriormente.
Con Vagrant te puedes descargar directamente una máquina configurada de esta lista. Por ejemplo,
vagrant box add centos65 https://github.com/2creatives/vagrant-centos/releases/download/v6.5.1/centos65-x86_64-20131205.box
El formato determinará en qué tipo de hipervisor se puede ejecutar; en
general, Vagrant usa VirtualBox, y los .box se ejecutan precisamente
en ese formato. Otras imágenes están configuradas para trabajar con
VMWare, pero son las menos. A continuación,
vagrant init centos65
crea un fichero Vagrantfile (y así te lo dice) que permite trabajar
y llevar a cabo cualquier configuración adicional. Una vez hecho eso
ya podemos inicializar la máquina y trabajar con ella (pero antes voy
a apagar la máquina Azure que tengo ejecutándose desde que empecé a
contar lo anterior)
vagrant up
y se puede empezar a trabajar en ella con
vagrant ssh
Instalar una máquina virtual Debian usando Vagrant y conectar con ella.
Una vez creada la máquina virtual se puede entrar en ella y configurarla e instalar todo lo necesario. Pero, por supuesto, sabiendo lo que sabemos sobre provisionamiento, Vagrant permite provisionarla de muchas maneras diferentes. En general, Vagrant usará opciones de configuración diferente dependiendo del provisionador, subirá un fichero a un directorio temporal del mismo y lo ejecutará (tras ejecutar todo lo necesario para el mismo).
La provisión tiene lugar cuando se alza una máquina virtual (con
vagrant up) o bien explícitamente haciendo vagrant provision. En
cualquier caso se lee del Vagrantfile y se llevan a cabo las acciones
especificadas en el fichero de configuración.
En general, trabajar con un provisionador requiere especificar de cuál
se trata y luego dar una serie de órdenes específicas. Comenzaremos
por el
shell, que
es el más simple y, en realidad, equivale a entrar en la máquina y dar
las órdenes a mano. Instalaremos, como hemos hecho en otras ocasiones,
el utilísimo editor emacsusando este
Vagrantfile:
VAGRANTFILE_API_VERSION = "2"
Vagrant.configure(VAGRANTFILE_API_VERSION) do |config|
config.vm.box = "centos65"
config.vm.provision "shell",
inline: "yum install -y emacs"
end
Recordemos que se trata de un programa en Ruby en el cual configuramos
la máquina virtual. La 4ª línea indica el nombre de la máquina con la
que vamos a trabajar (que puede ser la usada en el caso anterior);
recordemos también que, por omisión, se trabaja con VirtualBox (si se
hiciera con algún otro tipo de hipervisor habría que usar el plugin
correspondiente e inicializar la máquina de alguna otra forma). La
parte en la que efectivamente se hace la provisión va justamente a
continuación. La orden config.vm.provision indica que se va a usar
el sistema de provisión del shell, es decir, órdenes de la línea de
comandos; se le pasa un hash en Ruby (variable: valor, tal como en
JavaScript, separados por comas) en el que la clave inline indica el
comando que se va a ejecutar, en este caso yum, el programa para
instalar paquetes en CentOS, y al que se le indica -y para que
conteste Yes a todas las preguntas sobre la instalación.
Este Vagrantfile no necesita nada especial para ejecutarse: se le
llama directamente cuando se ejecuta vagrant up o explícitamente
cuando se llama con vagrant provision. Lo único que hará es instalar
este programa bajándose todas sus dependencias (y tardará un rato).
Crear un script para provisionar nginx o cualquier otro servidor
web que pueda ser útil para alguna otra práctica
El provisionamiento por shell admite muchas más opciones: se puede usar un fichero externo o incluso alojado en un sitio web (por ejemplo, un Gist alojado en GitHub). Por ejemplo, este para provisionar nginx y node (no leer hasta después de hacer el ejercicio anterior).
El problema con los guiones de shell (y no sé por qué diablos pongo guiones si pongo shell, podía poner scripts de shell directamente y todo el mundo me entendería, o guiones de la concha y nadie me entendería) es que son específicos de una máquina. Por eso Vagrant permite muchas otras formas de configuración, incluyendo casi todos los sistemas de provisionamiento populares (Chef, Puppet, Ansible, Salt) y otros sistemas con Docker, que también hemos visto. La ventaja de estos sistemas de más alto nivel es que permiten trabajar independientemente del sistema operativo. Cada uno de ellos tendrá sus opciones específicas, pero veamos cómo se haría lo anterior usando el provisionador chef-solo.
Para empezar, hay que provisionar la máquina virtual para que funcione con chef-solo y hay que hacerlo desde shell o Ansible; este ejemplo que usa este fichero shell puede provisionar, por ejemplo, una máquina CentOS.
Una vez preinstalado chef (lo que también podíamos haber hecho con
una máquina que ya lo tuviera instalado, de las que hay muchas en vagrantbox.es
y de hecho es la mejor opción porque chef-solo no se puede instalar en la
versión 6.5 de CentOS fácilmente por no tener una versión actualizada de Ruby)
incluimos en el Vagrantfile. las órdenes para usarlo en
este Vagrantfile
VAGRANTFILE_API_VERSION = "2"
Vagrant.configure(VAGRANTFILE_API_VERSION) do |config|
config.vm.box = "centos63"
config.vm.provision "chef_solo" do |chef|
chef.add_recipe "emacs"
end
end
Este fichero usa un bloque de Ruby para pasarle variables y
simplemente declara que se va a usar la receta emacs, que
previamente tendremos que haber creado en un subdirectorio cookbooks
que descienda exactamente del mismo directorio y que contenga
simplemente package 'emacs' que tendrá que estar en un fichero
cookbooks/emacs/recipes/default.rb
Con todo esto se puede configurar emacs.
Pero, la verdad, seguro que es más fácil hacerlo en Ansible y/o en otro sistema operativo que no sea CentOS porque yo, por lo pronto, no he logrado instalar chef-solo en ninguna de las máquinas pre-configuradas de VagrantBoxes.
Configurar tu máquina virtual usando vagrant con el provisionador chef.
Desde Vagrant se puede crear también una
caja base con lo
mínimo necesario para poder funcionar, incluyendo el soporte para ssh
y provisionadores como Chef o Puppet. Se puede crear directamente en
VirtualBox y usar
vagrant package
para empaquetarla y usarla para su consumo posterior.
A donde ir desde aquí
Este es el último tema del curso, pero a partir de aquí se puede seguir aprendiendo sobre DevOps en el blog o en IBM. Libros como DevOps for Developers pueden ser también de ayuda.
Este capítulo es suficientemente extenso para necesitar varios hitos del proyecto. Tras terminar la sección sobre Ansible, se va a la práctica de provisionamiento.
Si no lo has hecho ya, es hora de comenzar la última práctica.