Desarrollo basado en pruebas
Objetivos
De la asignatura
- Conocer los conceptos relacionados con el proceso de virtualización tanto de software como de hardware y ponerlos en práctica.
Específicos
- Entender el concepto de DevOps.
- Usar herramientas para gestión de los ciclos de desarrollo de una aplicación y entender cuales son estos.
- Aprender a usar integración continua en cualquier aplicación.
Introducción
Si no lo has hecho antes, conviene que en este momento aprendas git y te abras una cuenta en GitHub.
Los ciclos de desarrollo de software actuales son ágiles y rápidos: continuamente se están arreglando errores, programando nuevas características y desplegándolas, inicialmente para probarlas y eventualmente en producción. Para que esto sea posible este ciclo de vida debe estar automatizado en todo lo posible, de forma que todas las fases se hagan esencialmente sin intervención humana y se minimice la posibilidad de que haya en el proceso errores que sean costosos de arreglar una vez echado a andar un sistema. La aparición de la nube ha hecho que en varias, o en todas, las partes del proceso, aparezcan recursos elásticos y disponibles bajo demanda, algunos de ellos gratuitos.
Por eso, en esta parte del curso, veremos cómo desarrollar según la metodología basada en pruebas con los entornos de computación en nube y cómo configurarlos y usarlos para hacer más rápida y eficiente el trabajo de un equipo de desarrollo, test y sistemas.
El desarrollo basado en pruebas entra en relación con la computación nube dentro del concepto de DevOps, que abarca tanto sistemas, es decir, el soporte físico donde se van a ejecutar las aplicaciones, como desarrollo y test y que está a caballo entre los dos primeros. En primer lugar, DevOps implica la automatización de las tareas de creación de un puesto de trabajo para desarrollo, pero también la sistematización de los entornos de pruebas y de despliegue y de las tareas de configuración relacionadas con la misma, todo ello en un entorno de desarrollo ágil. En concreto, DevOps comprende los 7 aspectos siguientes, vistos en la página de una herramienta, Rex, que es parte de la panoplia usada para esos menesteres:
-
Automatización de tareas relacionadas con el desarrollo. En resumen, que no haya que recordar o tener apuntados en una libreta comandos para hacer todo tipo de cosas (instalación de librerías o configuración de una máquina) sino que haya scripts que lo homogeneicen y automaticen.
-
Virtualización: uso de recursos virtuales para almacenamiento, publicación y, en general, todos los pasos del desarrollo y despliegue de software.
-
Provisionamiento de los servidores: los servidores virtuales a los que se despliegue deben estar preparados con todas las herramientas necesarias para publicar la aplicación.
-
Gestión de configuraciones: la gestión de las configuraciones de los servidores y las órdenes para provisionamiento deben estar controladas por un sistema de gestión de versiones que permita pruebas y también controlar en cada momento el entorno en el que efectivamente se está ejecutando el software.
-
Despliegue en la nube: publicación de aplicaciones en servidores virtuales.
-
Ciclo de vida del software definición de las diferentes fases en la vida de una aplicación, desde el diseño hasta el soporte.
-
Despliegue continuo: el ciclo de vida de una aplicación debe ir ligado a ciclos de desarrollo ágiles en los que cada nueva característica se introduzca tan pronto esté lista y probada; el despliegue continuo implica integración continua de las nuevas características y arreglos, tanto en el software como el hardware.
En este tema veremos la mayoría; en los siguientes se verá la gestión de configuraciones, provisionamiento de los servidores, despliegue continuo y virtualización.
Este tema (y bastantes más) están cubiertos en el curso de calidad en el software que se ha impartido en octubre-noviembre de 2019.
Entornos virtuales de desarrollo
Una de las partes esenciales de la cultura DevOps es la gestión de configuraciones y posteriormente, la automatización. El uso de entornos virtuales cubre las dos necesidades: te permite independizar la versión usada de la que proporcione el sistema, instalarla sin necesidad de tener privilegios de superusuario, compartirla entre todos los miembros del equipo y también automatizar la tarea de instalación del mismo mediante el uso de una sola orden que seleccione la versión precisa que se va a usar.
Estos entornos virtuales vienen del hecho de que los lenguajes de scripting o también conocidos como lenguajes interpretados tales como Perl, Python y Ruby tienen ciclos de desarrollo muy rápidos que hacen que a veces convivan en producción diferentes versiones de los mismos, incluso versiones major. Eso hace complicado desarrollar e incluso probar los programas que se desarrollan: si el sistema operativo viene con Perl 5.14, puede que haga falta probar o desarrollar para 5.16 o 5.18 o incluso probar la versión más avanzada.
Por eso desde hacer cierto tiempo se han venido usando entornos virtuales de desarrollo tales como:
- virtualenv para Python,
- nvm,
ny nave para node.js, phpenvpara, lo adivinaste, PHP,- rbenv y RVM para Ruby
- y plenv y perlbrew para Perl.
Generalmente, estos programa funcionan instalando binarios en directorios del usuario y modificando el camino de ejecución para que se usen estas versiones en vez de las instaladas en el sistema. En la mayoría de los casos se coordinan también con el shell para mostrar la versión que se está ejecutando en la línea de órdenes o para llevar a cabo autocompletado.
Una vez instalados, estos programas permiten instalar fácilmente nuevas versiones de tu lenguaje de programación (con las librerías asociadas) y probar un programa en todas ellas. Se usan principalmente para reflejar localmente los entornos que se usan en producción; por ejemplo, usar en el entorno de desarrollo local la misma versión y librerías que nos vamos a encontrar en un PaaS tal como los que veremos a continuación.
Instalar alguno de los entornos virtuales de node.js (o de cualquier
otro lenguaje con el que se esté familiarizado) y, con ellos,
instalar la última versión existente, la versión minor más actual
de la 4.x y lo mismo para la 0.11 o alguna impar (de desarrollo).
Generalmente, las librerías asociadas a una aplicación determinada, es decir, las dependencias, siguen un método similar. En vez de instalar en el sistema todas las librerías necesarias (o instalar una cada vez que hay algún error), la mayor parte de los entornos de programación incluyen alguna forma de definir qué librerías (o módulos) necesitan y qué versiones mínimas, máximas o exactas deben tener.
Incidentalmente, el hecho de que todo sea software libre ayuda a que en ningún paso de este proceso haya que decidir qué licencia o modelo de pago o cosas similares hay que usar.
Vamos a hacer una aplicación: gestionar porras de fútbol
Primero, debe constar que esta aplicación solo está aquí a efectos de ejemplo, igual que el lenguaje en el que está escrita. Si se quiere usar cualquier otro lenguaje o aplicación, se puede hacer. Si quieres usar JavaScript, este curso o este libro te pueden ayudar, aunque cualquier otro también.
Una porra de fútbol básicamente tiene un partido, que tendrá un nombre y si acaso una fecha o descripción (por ejemplo, Jaén-Osasuna Copa 2014) y luego los participantes votan por un resultado determinado, JJ, 2-1, por ejemplo. Este sería el modelo sobre el que vamos a basar la aplicación.
El objeto básico, por tanto, será la Apuesta que irá asociada a un
Partido.
La aplicación podrá tener, o no, un interfaz web, pero por lo pronto, y a efectos de la prueba continua de más adelante, vamos a quedarnos solo con un pequeño programa que sirva para comprobar que funciona.
Configuración de una aplicación en node
Podemos almacenar esta información en una base de datos como SQLite (la clásica).
Este “sistema de gestión de bases de datos” se usa solamente a efectos educativos. No es una buena idea usarlo en producción
Para instalarla, npm install sqlite que es la forma
como se instalan los módulos de node. Además, se instala en
local. Pero el objeto del desarrollo moderno es asegurarse de que todo
lo necesario para programar algo está presente. Por eso, se usan
ficheros que describen qué se usa y, en general, que es necesario
instalar y tener para ejecutarlo. En node se usa un fichero en formato
JSON tal como este:
{
"author": "J. J. Merelo <jjmerelo@gmail.com> (https://github.com/JJ/desarrollo-basado-pruebas)",
"name": "porrio",
"description": "Apuesta en una porra",
"version": "0.0.1",
"repository": {
"url": "git://github.com/JJ/desarrollo-basado-pruebas.git"
},
"main": "./Apuesta.js",
"scripts": {
"test": "make test"
},
"dependencies": {"sqlite3": "~3.0"},
"devDependencies": {},
"optionalDependencies": {},
"engines": {
"node": ">=0.8"
}
}
Las partes que más nos interesan están hacia el final: las
dependencias diversas (dependencies). Es un hash que dice qué
módulo se usan (en este caso, sqlite sólo) y qué versiones harán
falta. Al desplegarse, el entorno dependerá de muchas cuestiones y hay
que asegurarse de que donde va a acabar el programa tiene todo lo
necesario. En caso de que no lo tuviera, el programa no se instalará.
A este nivel, la descripción del entorno de trabajo ya constituye en sí un test: donde se va a desplegar lo tiene o no lo tiene, en cuyo caso no se permitirá la ejecución.
Este fichero, además, permite instalar todas las dependencias usando
solo npm install .. Casi todos los lenguajes habituales tienen algún
sistema similar: bundle para Ruby o cpanm para Perl, por ejemplo.
Crear una descripción del módulo usando package.json. En caso de
que se trate de otro lenguaje, usar el método correspondiente.
package.json nos sirve para llevar un cierto control de qué es lo
que necesita nuestra aplicación y, por tanto, nos va a ser bastante
útil cuando digamos de desplegarlo o testearlo en la nube.
No solo eso, sino que es la referencia para otra serie de
herramientas, como las herramientas de construcción. Las herramientas
de construcción o de control de tareas se vienen usando
tradicionalmente en todos los entornos de programación. Quién no ha
usado alguna vez make o escrito un Makefile; lo que ocurre es que
tradicionalmente se dedicaban exclusivamente a la compilación. Hoy en
día el concepto de construcción es más amplio e incluye tareas que
van desde el uso de diferentes generadores (de hojas CSS a partir de
un lenguaje, por ejemplo) hasta la minificación o “compresión” de un
programa hasta que ocupe el mínimo espacio posible, para que sea más
amigable para móviles y otros dispositivos sin mucho ancho de banda.
Todos los lenguajes de programación tienen su propia herramienta de construcción, pero en node.js se utilizan principalmente dos: Grunt y Gulp.
Aquí podíamos hacer una breve disquisición sobre el código y la configuración, algo a lo que nos vamos a enfrentar repetidamente en la nube. ¿Un fichero de construcción es, o debe ser, configuración o código? Diferentes herramientas hacen diferentes aproximaciones al tema:
gruntes, sobre todo, configuración, mientras quegulpes, sobre todo, código.
Algo fundamental en todo proyecto es la documentación; para empezar,
vamos a usar grunt para documentar el código. Tras la instalación de
grunt, que no viene instalado por defecto en nodejs, se puede usar
directamente.
npm install -g grunt-cli
-g indica que se trata de una instalación global, aunque también se
puede instalar localmente.
Igual que make usa
Makefiles, grunt usa Gruntfile.js tal como este
'use strict';
module.exports = function(grunt) {
// Configuración del proyecto
grunt.initConfig({
pkg: grunt.file.readJSON('package.json'),
docco: {
debug: {
src: ['*.js'],
options: {
output: 'docs/'
}
}
}
});
// Carga el plugin de grunt para hacer esto
grunt.loadNpmTasks('grunt-docco');
// Tarea por omisión: generar la documentación
grunt.registerTask('default', ['docco']);
};
Es necesario instalar docco si queremos que funcione. Y grunt
enfoca el procesamiento de las tareas como una serie de plugins que
hay que instalar, en este caso grunt-docco. Para instalarlos se usa
la herramienta habitual de instalación en node, npm, pero una vez
que usamos package.json, npm puede editarlo y cambiar la
configuración automáticamente si lo usamos de esta forma
npm install docco grunt-docco --save-dev
El --save-dev indica que se guarde la configuración correspondiente
en package.json, donde efectivamente se puede ver:
"devDependencies": {
"docco": "~0.6",
"grunt-docco": "~0.3.3"
},
El fichero que se ve arriba tiene tres partes: la definición de la tarea (en este caso, la que genera la documentación), la carga de la tarea y finalmente el registro de la tarea.
Vayamos con la primera parte. Primero, le indicamos cuál es el fichero
package.json que usamos. Este fichero tiene una serie de variables
de configuración que podremos usar en el Gruntfile (pero que, por lo
pronto, no vamos a hacerlo). Luego, definimos la tarea llamada
docco, que a su vez tiene una subtarea llamada debug: toma los
fuentes contenidos en el array indicado y deposita la salida en el
directorio que le indicamos. No existe en Grunt una forma general de
expresar este tipo de dependencias como en los Makefiles, solo una
buena práctica: usar src, por ejemplo, para las fuentes.
La siguiente parte carga el plugin de grunt necesario para ejecutar
docco. Y finalmente, con grunt.registerTask('default', ['docco']);
indicamos que la tarea que ejecuta docco es la que se ejecutará por
defecto simplemente ejecutando grunt. También se puede ejecutar con
grunt docco o grunt docco:debug que sacará esto en el terminal:
bash$ grunt docco
Running "docco:src" (docco) task
docco: Apuesta.js -> docs/Apuesta.html
docco: Gruntfile.js -> docs/Gruntfile.html
y producirá una documentación tal como esta.
La automatización de Grunt se puede usar tanto para prueba como para despliegue. Pero hay también otras formas de realizar pruebas en la nube, y lo veremos a continuación.
Configuración en Scala: Usando Scala Build Tool
A diferencia de node.js y de otros
lenguajes, Scala tiene una herramienta
de configuración y construcción que forma parte del lenguaje y que se
llama,
precisamente,
sbt o Scala Build Tool. sbt incluye
un DSL (Domain Specific Language) para configurar la aplicación, las
versiones de todo que usa, inclusive el propio lenguaje, y las
dependencias, y además un entorno de línea de órdenes desde el que se
puede probar y ejecutar la aplicación.
Los ficheros de configuración para sbt llevan esa extensión y se
suelen situar en el directorio principal. Para la aplicación
mencionada anteriormente, este es el fichero:
import Dependencies._
val circeVersion = "0.12.3"
libraryDependencies ++= Seq(
"io.circe" %% "circe-core",
"io.circe" %% "circe-generic",
"io.circe" %% "circe-parser"
).map(_ % circeVersion)
libraryDependencies +=
"org.scalatest" %% "scalatest" % "3.2.0" % Test
lazy val root = (project in file(".")).
settings(
inThisBuild(List(
organization := "com.jjmerelo",
scalaVersion := "2.12.10",
version := "0.1.0"
)),
name := "Hitos",
)
cancelable in Global := true
sbt usa el propio lenguaje Scala para su configuración, y tras
declarar la organización que se va a usar y la versión del propio
paquete, declara una serie de versiones. Las declaraciones de
dependencia de variables en libraryDependencies indican el paquete
(tal como io.circe), el módulo específico (tal como circe-core) y
finalmente la versión. El resto son opciones, de las cuales la más
interesante es la última que permite que se interrumpa el programa
desde sbt.
Incidentalmente,
sbtes claramente una herramienta de construcción junto con una de gestión de dependencias. No es un gestor de tareas, aunque todas las tareas relacionadas con uno y otro se pueden lanzar desde él.
Al ejecutar sbt en el directorio donde se encuentre este fichero se
cargará y se interpretará ese fichero y aparecerá una línea de
órdenes, desde la que podemos ejecutar el programa o
testearlo. También se pueden compilar los fuentes con sbt compile
directamente desde la línea de órdenes.
Descargar el repositorio de ejemplo anterior, instalar las herramientas necesarias
(principalmente Scala y sbt) y ejecutar el ejemplo desde
sbt. Alternativamente, buscar otros marcos para REST en Scala tales
como Finatra o Scalatra y probar los ejemplos que se incluyan en el
repositorio.
Usando TDD en la práctica
El desarrollo basado en pruebas es una metodología que se integra con el desarrollo en la nube que hemos venido viendo de forma inconsútil (en inglés esto queda mejor; seamless). Hace falta pasar las pruebas para hacer el despliegue, pero también para integrar código. Las pruebas son a diferente nivel, pero las que vamos a usar, pruebas unitarias, consisten en llamar a una función con diferentes valores y comprobar los resultados esperados con los obtenidos. Los resultados pueden ser de todo tipo: desde simples escalares respuesta a una función hasta cambio en el DOM de una página cuando se envía un JSON desde una web. Cada uno tiene sus estrategias, pero al final se trata de crear una serie de pruebas para que lo que nosotros queremos que haga la aplicación efectivamente lo haga.
El desarrollo basado en pruebas consiste en escribir los tests antes que el código que hace que esos tests no fallen. No siempre se hace así, claro, pero el trabajar así permite tener claro qué funcionalidades queremos, cómo queremos que respondan y qué contratos o aserciones van a ser verdaderas cuando se ejecute el código antes siquiera de escribirlo.
Lejos de ser una pérdida de tiempo, usar pruebas ahorra tiempo de programación, al evitar errores en producción y el tiempo que se pierde en localizarlos y evitarlos.
En la mayoría de los entornos de programación y especialmente en node, que es en el que nos estamos fijando, hay dos niveles en el test: el primero es el marco de pruebas y el segundo la librería de pruebas que efectivamente se está usando.
Vamos a ir al nivel más bajo: el de las
aserciones. Hay
múltiples bibliotecas que se pueden
usar:
Chai,
Should.js,
Must.js y
assert que es la librería que
forma parte de la estándar de JS, y por tanto la que vamos a usar. Se
usa de la forma siguiente
var apuesta = require("./Apuesta.js"),
assert= require("assert");
var nueva_apuesta = new apuesta.Apuesta('Polopos','Alhama','2-3');
assert(nueva_apuesta, "Creada apuesta");
assert.equal(nueva_apuesta.as_string(), "Polopos: Alhama - 2-3","Creado");
console.log("Si has llegado aquí, han pasado todos los tests");
Este programa usa assert directamente y como se ve por la línea del
final, no hace nada salvo que falle. assert no da error si existe el
objeto, es decir, si no ha habido ningún error en la carga o creación
del mismo, y equal comprueba que efectivamente la salida que da la
función as_string es la esperada.
Hay un segundo nivel, el marco de ejecución de los tests. Los marcos son programas que, a su vez, ejecutan los programas de test y escriben un informe sobre cuáles han fallado y cuáles no con más o menos parafernalia y farfolla. Una vez más, hay varios marcos de testeo para nodejs (y, por supuesto, uno propio para cada uno de los lenguajes de programación, aunque en algunos están realmente estandarizados).
Cada uno de ellos tendrá sus promotores y detractores, pero Mocha y Jasmine parecen ser los más populares. Los dos usan un sistema denominado Behavior Driven Development, que consiste en describir el comportamiento de un sistema más o menos de alto nivel. Como hay que escoger uno y parece que Mocha es más popular, nos quedamos con este para escribir este programa de test.
var assert = require("assert"),
apuesta = require(__dirname+"/../Apuesta.js");
describe('Apuesta', function(){
// Testea que se haya cargado bien la librería
describe('Carga', function(){
it('should be loaded', function(){
assert(apuesta, "Cargado");
});
});
describe('Crea', function(){
it('should create apuestas correctly', function(){
var nueva_apuesta = new apuesta.Apuesta('Polopos','Alhama','2-3');
assert.equal(nueva_apuesta.as_string(), "Polopos: Alhama - 2-3","Creado");
});
});
});
Mocha puede usar diferentes librerías de test. En este caso hemos
escogido la que ya habíamos usado, assert. A bajo nivel, los tests
que funcionen en este marco tendrán que usar una librería de este
tipo, porque mocha funciona a un nivel superior, con funciones como
it y describes que describe, a diferentes niveles, qué hace el
test y cuál es el resultado que necesitamos. Se ejecuta con mocha y
el resultado de ejecutarlo será:
Apuesta
Carga
✓ should be loaded
Crea
✓ should create apuestas correctly
2 passing (6ms)
(pero con más colorines).
Y la verdad es que debería haber puesto los mensajes en español.
Además, te indica el tiempo que ha tardado lo que te puede servir para hacer un benchmark de tu código en los diferentes entornos en los que se ejecute.
Para la aplicación que se está haciendo para la asignatura, escribir una serie de aserciones y probar que efectivamente no fallan. Añadir tests para una nueva funcionalidad, probar que falla y escribir el código para que no lo haga. A continuación, ejecutarlos desde mocha (u otro módulo de test de alto nivel en el lenguaje que se esté usando), usando descripciones del test y del grupo de test de forma correcta. Si hasta ahora no has subido el código que has venido realizando a GitHub, es el momento de hacerlo, porque lo vamos a necesitar un poco más adelante.
Realizando las pruebas en Scala
En Scala, sbt realiza una función similar a npm en el mundo
node. Sin embargo, el lenguaje en sí es un poco más estricto y tiene
reglas más o menos precisas sobre dónde colocar los tests. Si las
fuentes están en src/main, las pruebas estarán en src/test en el
directorio correspondiente al nombre del paquete. Por ejemplo,
src/test/scala/info/CC_MII/ para el paquete info.CC_MII, o
simplemente scala/jjmerelo para el paquete jjmerelo, que es el de
aquí.
También Scala tiene diferentes formas de testear. Una similar a la que
hemos usado anteriormente se llama specs2, una basada en
comportamiento; así vemos la diferencia entre usar TDD (en la
anterior) y BDD (en esta). La usamos en
el ejemplo a continuación:
package jjmerelo
import io.circe._
import org.specs2._
class Hitos_IVSpec2 extends Specification { def is = s2"""
Especificación para comprobar Hitos_IV
El objeto tipo Hitos en hitos_iv debe
existir $exists """
var hitos_iv = new Hitos_IV
def exists = hitos_iv.hitos must beRight
}
Tras importar el módulo correspondiente a los tests, estos se agrupan
en una serie de sentencias must que serán ejecutadas
secuencialmente. En este caso tenemos una sola, en la que creamos una
instancia de la clase y comprobamos que efectivamente tiene los
valores que debe tener. Las órdenes must
comprueban el valor de diferentes tipos y devuelven los valores
correspondientes si se cumple ese comportamiento y si no se cumple. En
este caso se comprueba si el resultado del valor ha sido correcto
(correspondiente, en Scala, al tipo Right).
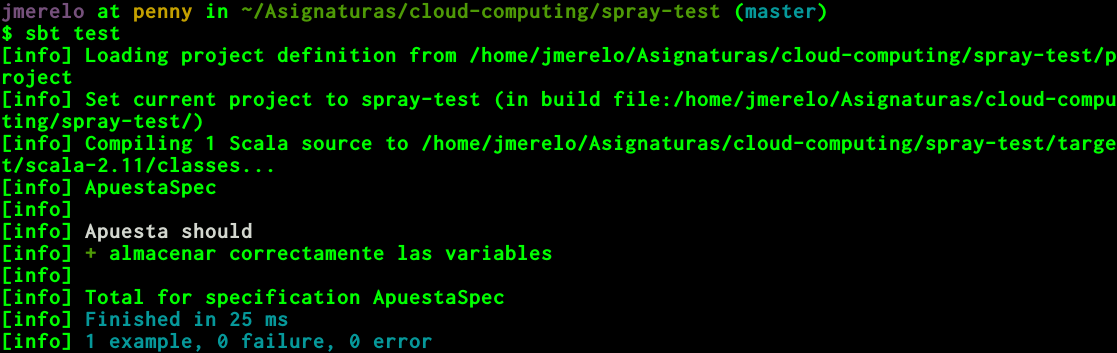
Se ejecutaría con sbt test o ejecutando test desde sbt; el
resultado sería:
Bibliografía y otros recursos
Algunos recursos a los que puedes acceder desde la Biblioteca de la UGR:
- DevOps: a software architect’s perspective , un libro en general teórico y “a vista de pájaro” de la creación de equipos de desarrollo y aplicaciones basadas en esa filosofía.
- DevOps for developers también con poco código, pero con una visión a más bajo nivel de cómo organizar y montar grupos DevOps.
Esta página lista una serie de recursos útiles, incluyendo blogs y canales de IRC, aparte de diferentes herramientas que deben estar en el carcaj del arquero DevOps, aunque la mayoría de los enlaces a estos están atrasados (y uno está en chino, así que no tengo ni idea).
A dónde ir desde aquí
Este artículo te cuenta qué hacer cuando testear es complicado. Una serie de técnicas, como mocking, te ayudan a probar en circunstancias que podrían ser complicadas o simplemente específicas (como la hora del día).
Durante la realización de los ejercicios de este tema se habrá tenido que hacer el primer hito del proyecto de la asignatura, para pasar al segundo hito cuando se haya concluido.
A continuación se puede echar un vistazo a los PaaS, plataformas como servicio, que pueden resultar útiles en la misma. En este tema donde se explica cómo se pueden desplegar aplicaciones para prototipo o para producción de forma relativamente simple, o bien al tema dedicado a los contenedores, que es el siguiente en el temario de la asignatura.